- Published on
AWS Lambda Runtime Performance
- Authors

- Name
- Nigel Slack-Smith
- @nigelss
TL;DR: According to this specific analysis, Rust is the fastest, most consistent, and most efficient lambda runtime.
Updates
Friday, April 7, 2023
Update to the Code Optimisation section related to concurrent asynchronous calls to DynamoDB for Python. Switched from synchronous boto3 to asynchronous aiodynamo. This shift from a parallel approach to true asynchronous concurrency brings Python into closer alignment with other runtimes.
Overview
This post presents a performance analysis of four popular AWS Lambda runtime alternatives: Node.js, Python, Go, and Rust.
- Updates
- Background
- Functions, Measurements and Metrics
- Datasets
- Performance Analysis
- Mitigations
- Conclusions
- Credits
Like any benchmarking exercise, your results may vary depending on the input data, processes and methods used. If you have a specific project in mind, don't rely solely on these results. Always perform your own analysis to determine the best approach for your unique situation.
The source code used to generate these benchmarks is available on GitHub.
Background
I'll review some core concepts that are particularly relevant as we proceed. However, this post assumes a working knowledge of AWS serverless offerings in general.
As a developer or architect working with AWS Lambda, you have the flexibility to choose the runtime for developing and deploying your serverless functions. The choice of runtime can have a big impact on the performance of your final solution concerning:
- User experience
- Cost efficiency
- Environmental impact
Choosing the appropriate runtime can result in an enhanced user experience, reduced costs, and efficient use of computing time and resources.
Functions, Measurements and Metrics
To compare each runtime in this analysis, we have created four microservices for each runtime:
- Warmup - a function to prepare the AWS environment for a benchmark run
- Wave - a function that receives a JSON payload and returns the same payload in the response
- Save - a function that calculates a geohash and writes a record containing the geohash to a DynamoDB table
- Search - a function that performs a geospacial query on the DynamoDB table
We'll see the Save, Wave and Search functions referenced throughout this post.
The measurements obtained from a benchmarking run for each request against a runtime and function include:
- Duration - the amount of time it takes for the function to execute, excluding any initialisation or other processing by the AWS Lambda Service
- Init Duration - the amount of time it takes to prepare a new instance of a function for processing its first request
- Total Duration - the amount of time taken in Duration plus Init Duration where applicable
- Billed Duration - the amount of time billed by AWS for processing a request
- Cold Start Duration - the amount of time taken in Duration plus Init Duration for a new instance, otherwise 0 for an existing instance
- Max Memory Used - the maximum amount of RAM used while executing a request
Most of the metrics are standard calculations based on measurements for each runtime function, using one of the following: Percentile, Median, Mean, or Max.
The Performance Index metric calculates a compressed view of relative performance. The worst-performing function will have an index value of 1, and other functions will have an index calculated relative to the worst-performing function. For example, if function X has an index of 1 and function Y has an index of 2, we can say that Y is twice as performant as X. If function Z has an index of 4, then we can say that Z is four times as performant as X and twice as performant as Y.
The Performance Index can then be averaged across all functions for a given runtime, compressing the relative performance into a single number for each runtime.
Datasets
This analysis references two datasets:
- All128MB - a full benchmarking run with all lambda functions configured with 128MB memory
- All256MB - a full benchmarking run with all lambda functions configured with 256MB memory
You'll see the datasets named on each graph for clarity.
Each benchmarking run executes 500 requests per function at a concurrency rate of 10.
Performance Analysis
Expected Range
For this analysis, the expected range is the 10th to 90th percentile range with highlighting over the 20th to 80th percentile range. This provides a good direct comparison between results without being overwhelmed by outliers.
The set of graphs below shows the expected range for all 12 functions (3 functions per runtime).
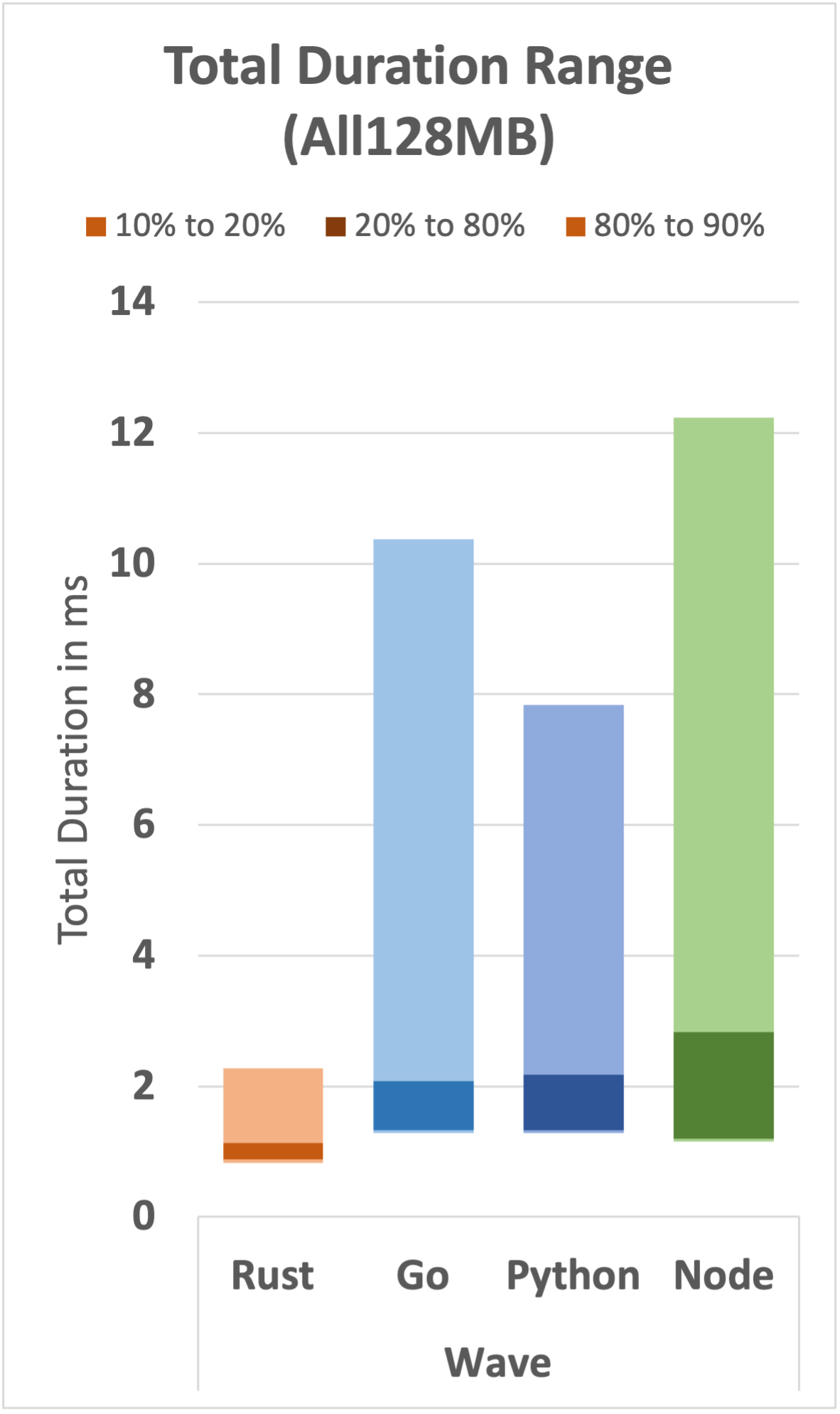
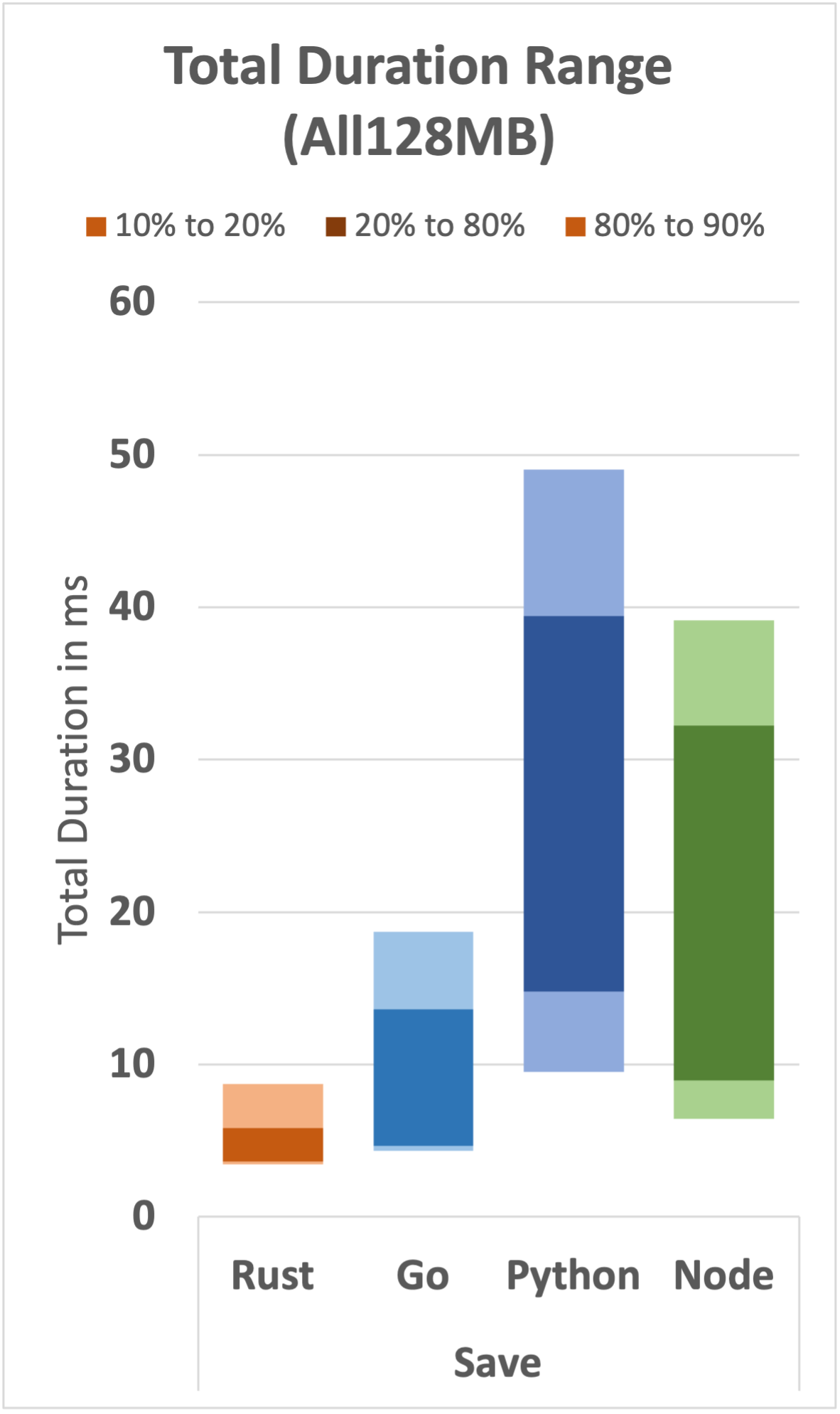
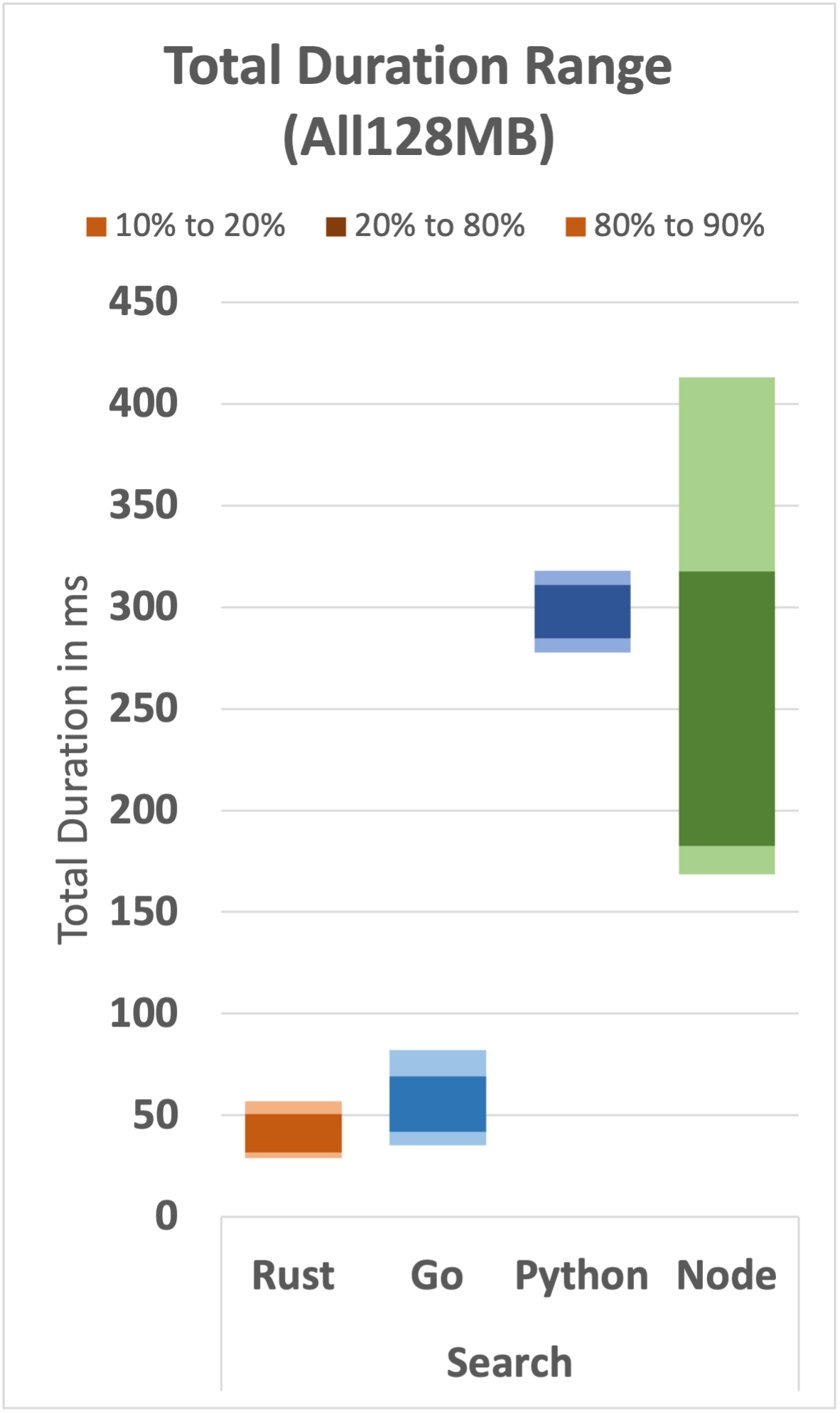
We can draw several observations from this set of graphs:
- Rust displays relatively very fast and very consistent performance over the expected range.
- For the simple wave function, Go, Python, and Node have long tails, even at the 80th percentile. It's only a few milliseconds, but it's an interesting difference.
- As the function complexity increases, a performance gap increases where Rust and Go remain reasonably performant compared with Python and Node.
- Node shows relatively inconsistent performance in the search function; it is generally faster than Python, but the range of values is relatively wide.
Outliers
In the Expected Range analysis, we intentionally excluded outliers to obtain a clearer view of performance within the normal range.
However, outliers are of critical importance, as this is where the user experience can be either won or lost, particularly during spikes in workload.
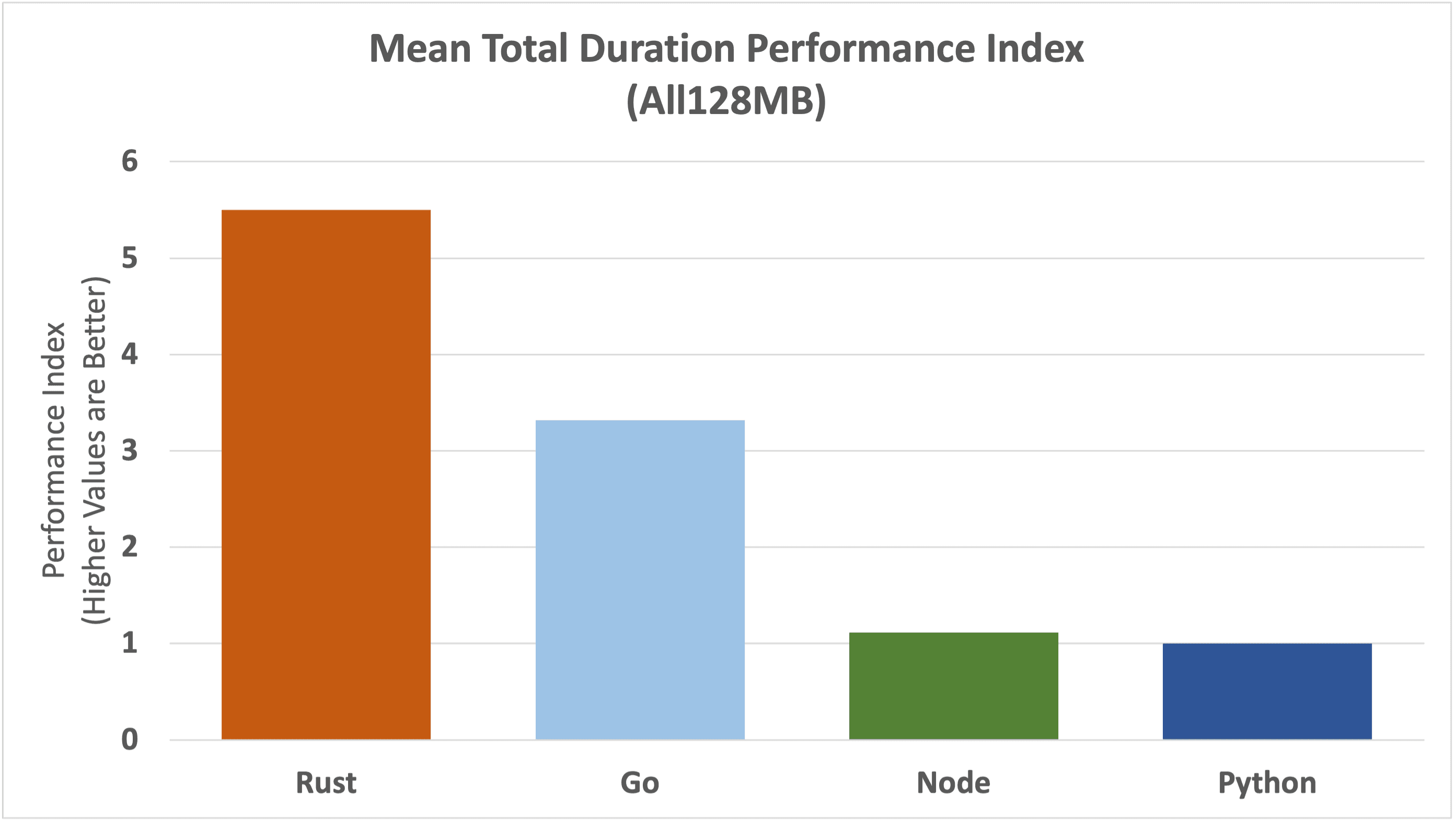
Worst Case Duration
We'll begin our analysis of outliers by directly examining the Performance Index for the most extreme worst-case.
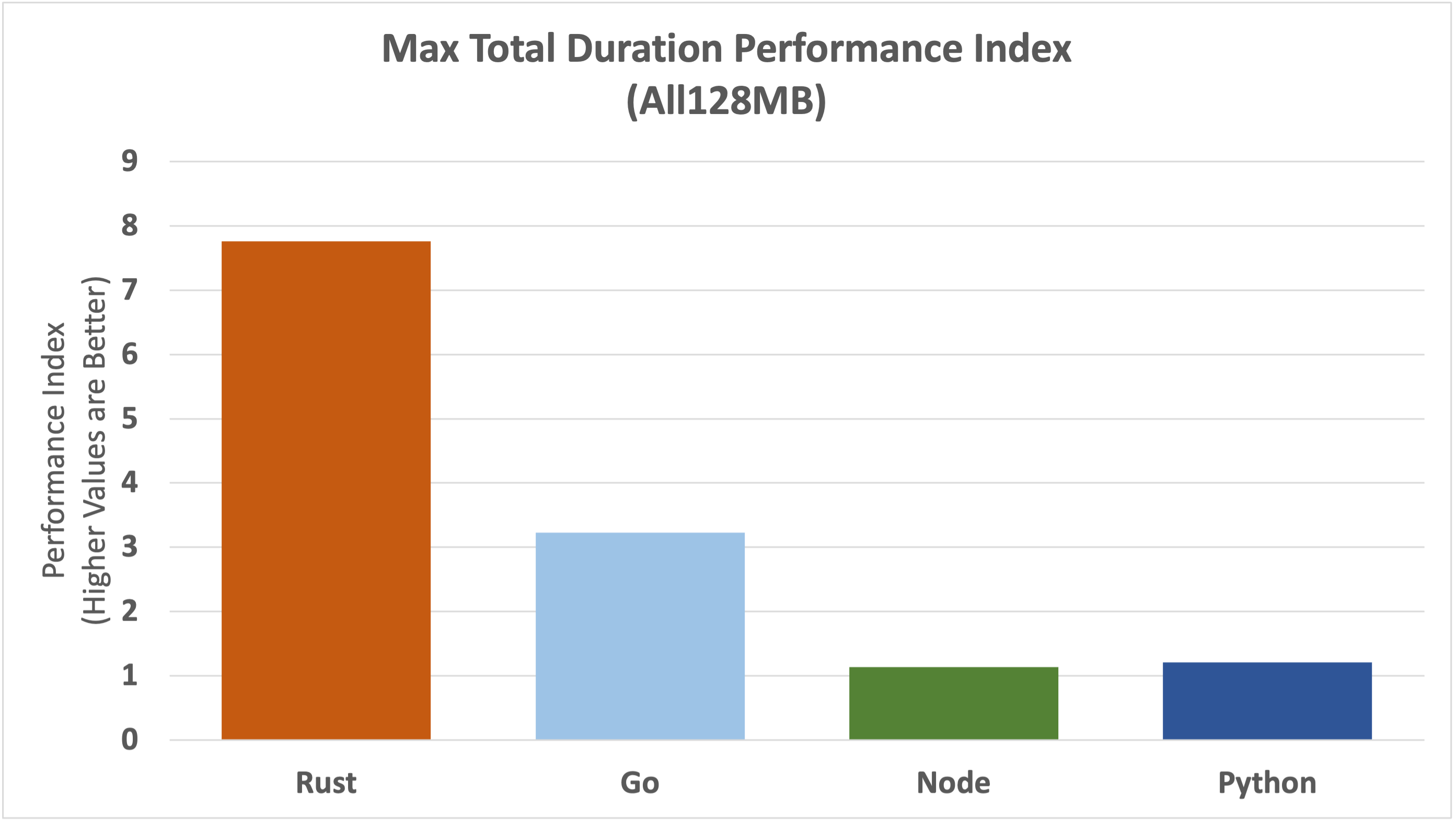
The graph above shows the relative dominance of Rust, followed not so closely by Go, with Node and Python performing the worst. Rust is almost 8 times faster than Node and Python, and 3.5 times faster than Go. Go is 3 times faster than Node and Python.
If we take a look at the underlying data by function and runtime, we can see the magnitude of the numbers and consider how this would translate to the user experience.
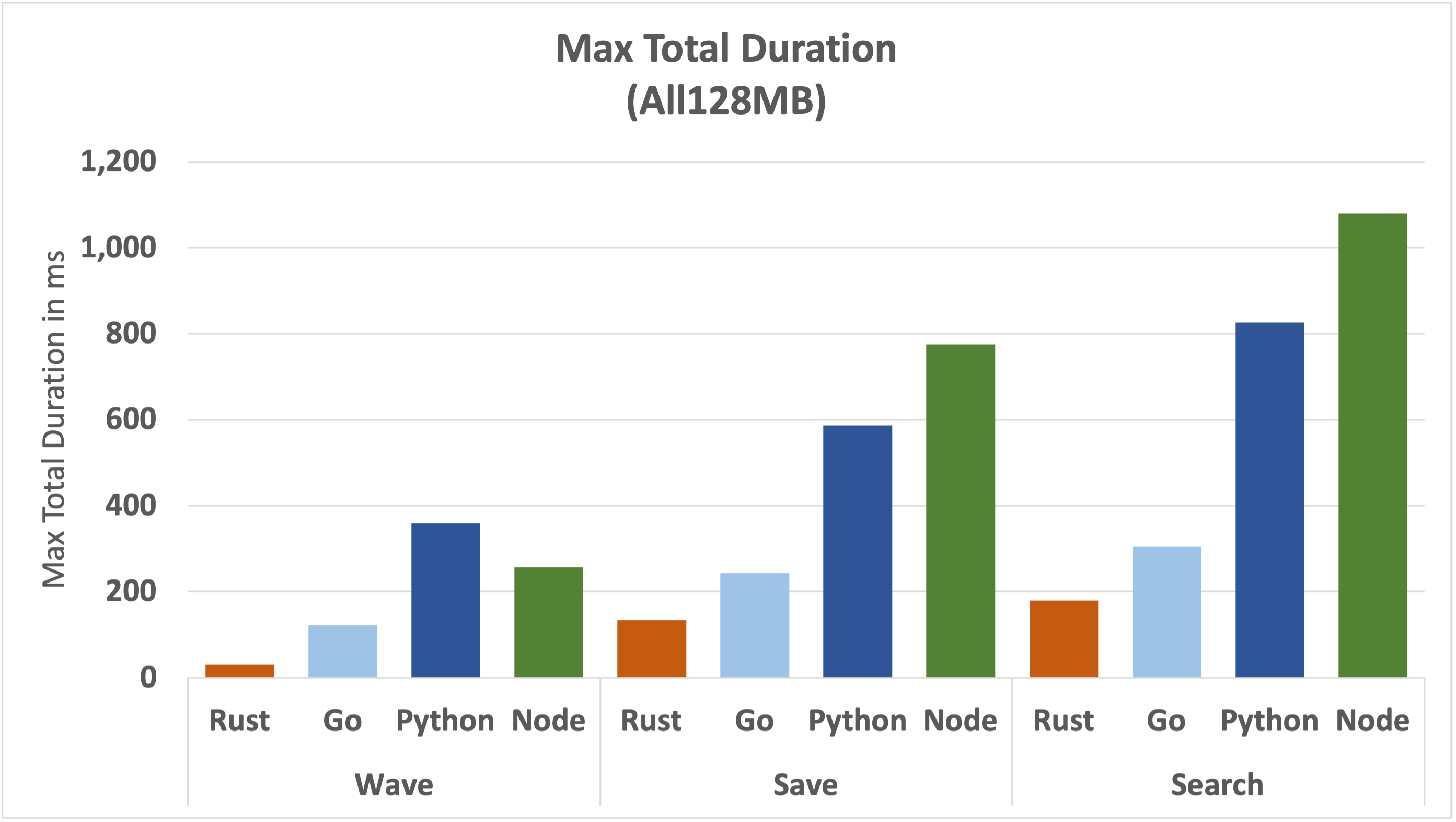
Rust maintains a sub 200ms worst-case for all functions, whereas Python and Node are above the 200ms for the simplest function, climbing to above 800ms and a full second for the most complex function. This isn't the full picture of an end-to-end user round-trip, but it has a direct impact on the bottom line.
Tail Analysis
Looking at the worst-case is useful as an easy comparison, but we need to dig a little deeper to make sure that we're not comparing wildly erratic numbers.
The following graphs visualise the performance tail from the 95th to the 100th percentile for each function. Due to the shape of our benchmark workload, we expect cold starts to impact performance above the 98th percentile, and that's what we see.
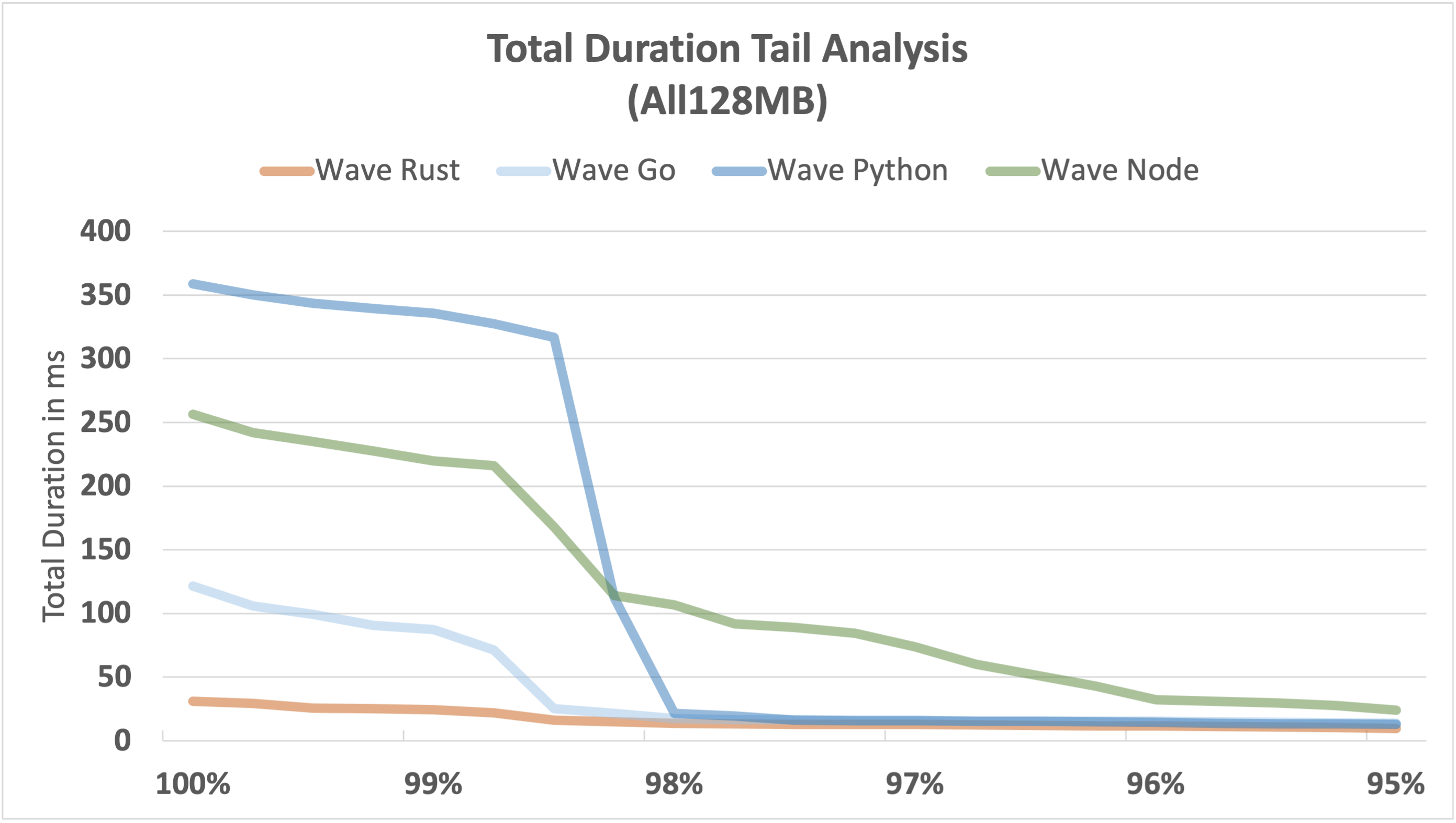
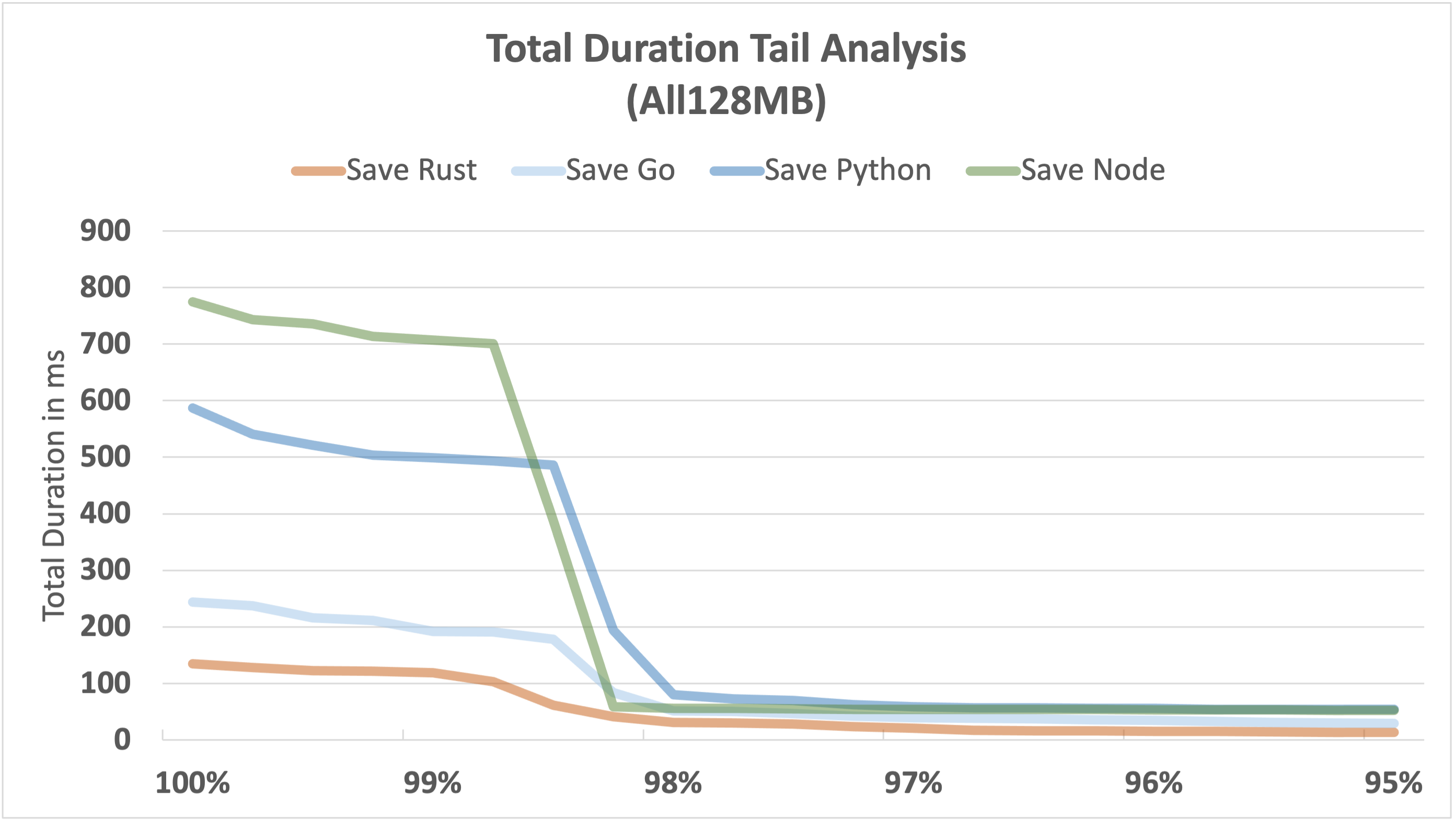
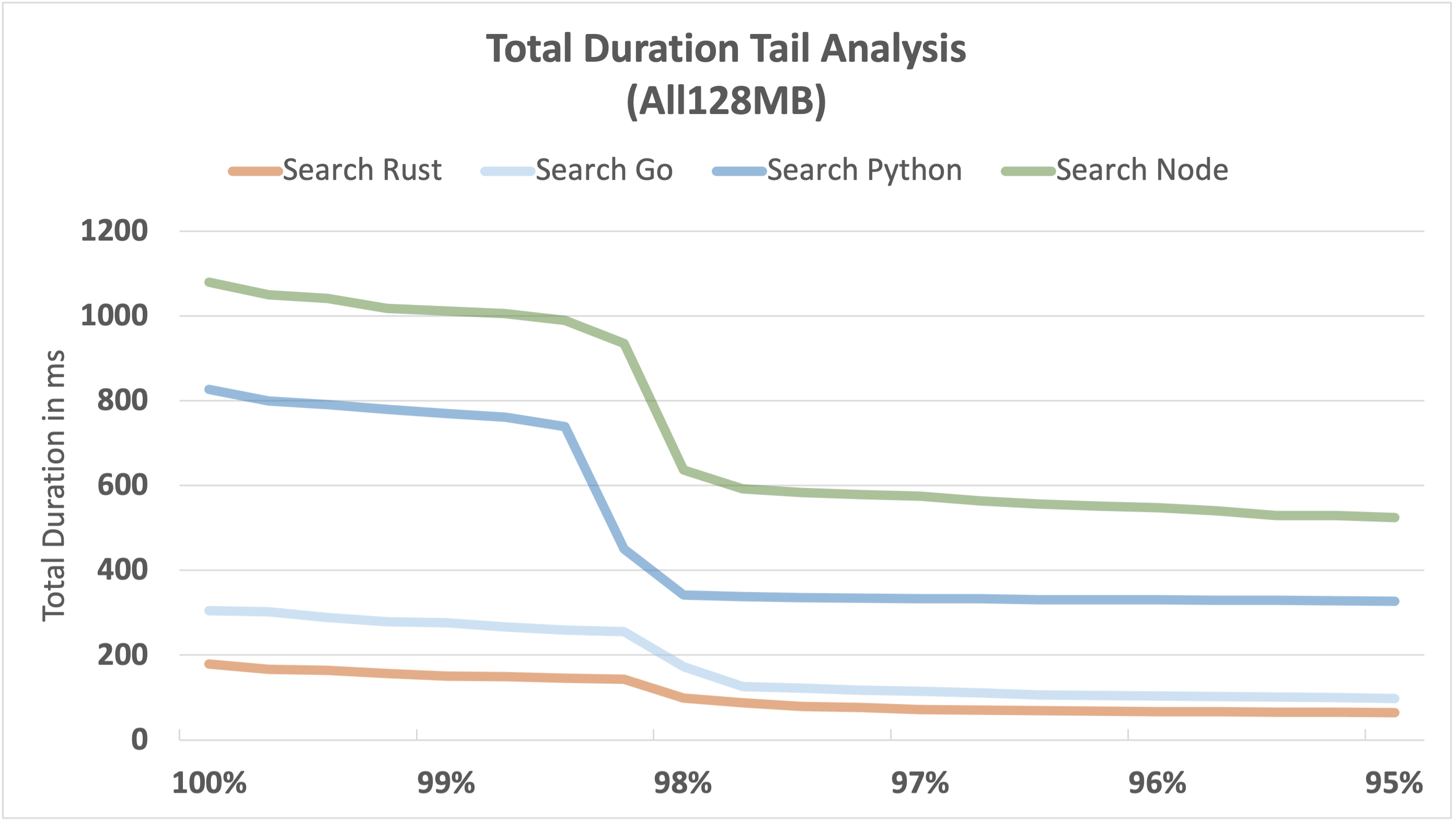
It's a fairly consistent picture across all 3 functions:
- Rust continues to be the most consistent and fastest performer, even at the tail end.
- Go is also consistently fast, but falls well short of Rust.
- Node and Python don't perform well at the tail end; the outliers become relatively large.
Cold Start
The lambda cold start issue is well known and can have a big impact on outliers as workloads increase. Spinning up a new instance of a function takes time, plus the first invocation of a function following an init can be slow.
There are mitigations for this issue, such as provisioned concurrency, which we will discuss later. For now, let's take a look at how the cold start issue is impacting each of the runtimes.
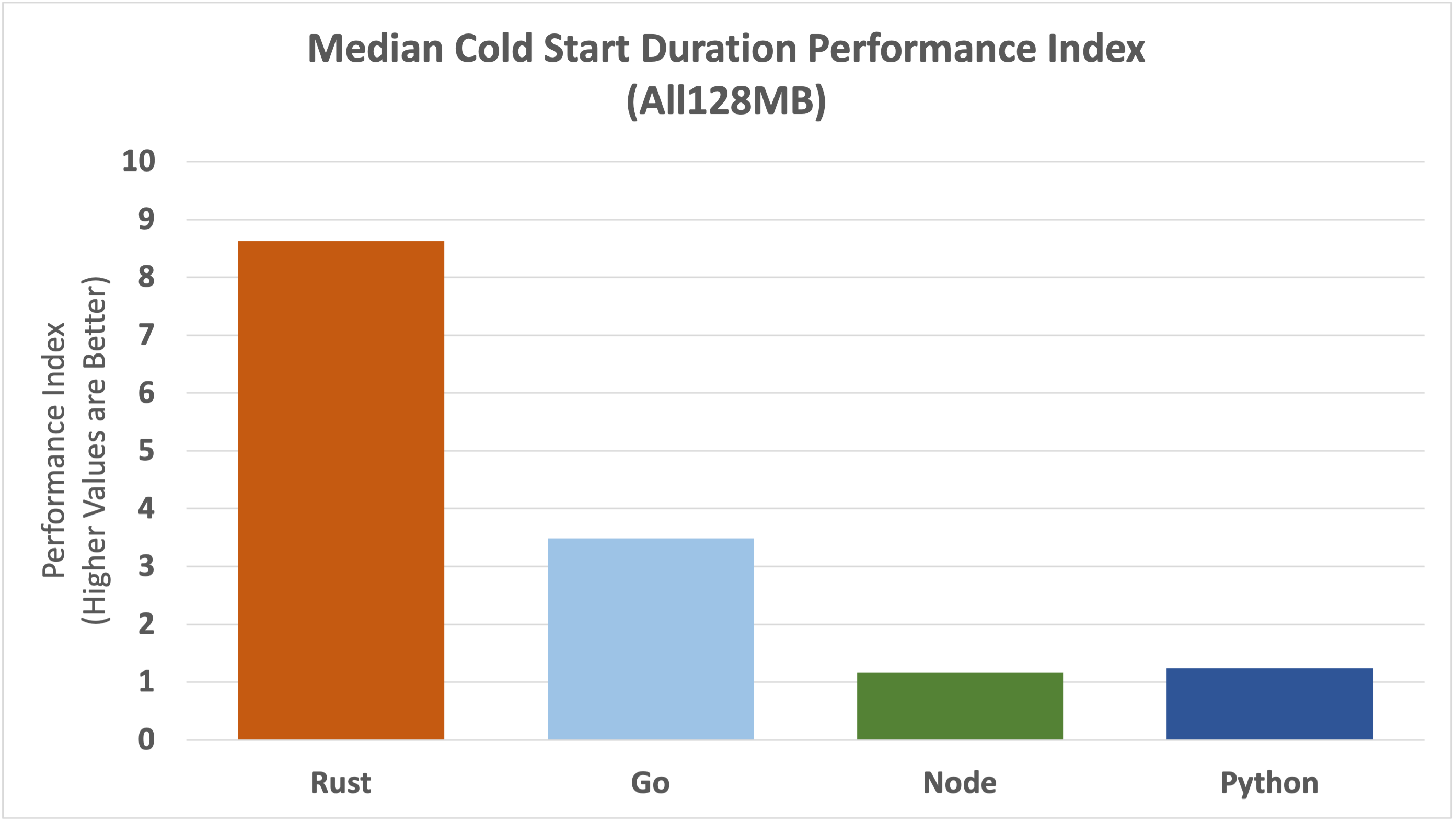
Rust has a huge relative advantage in cold start performance, around 8 times faster than Node and Python, and almost 3 times faster than Go.
Let's look at the underlying data to appreciate the magnitudes involved.
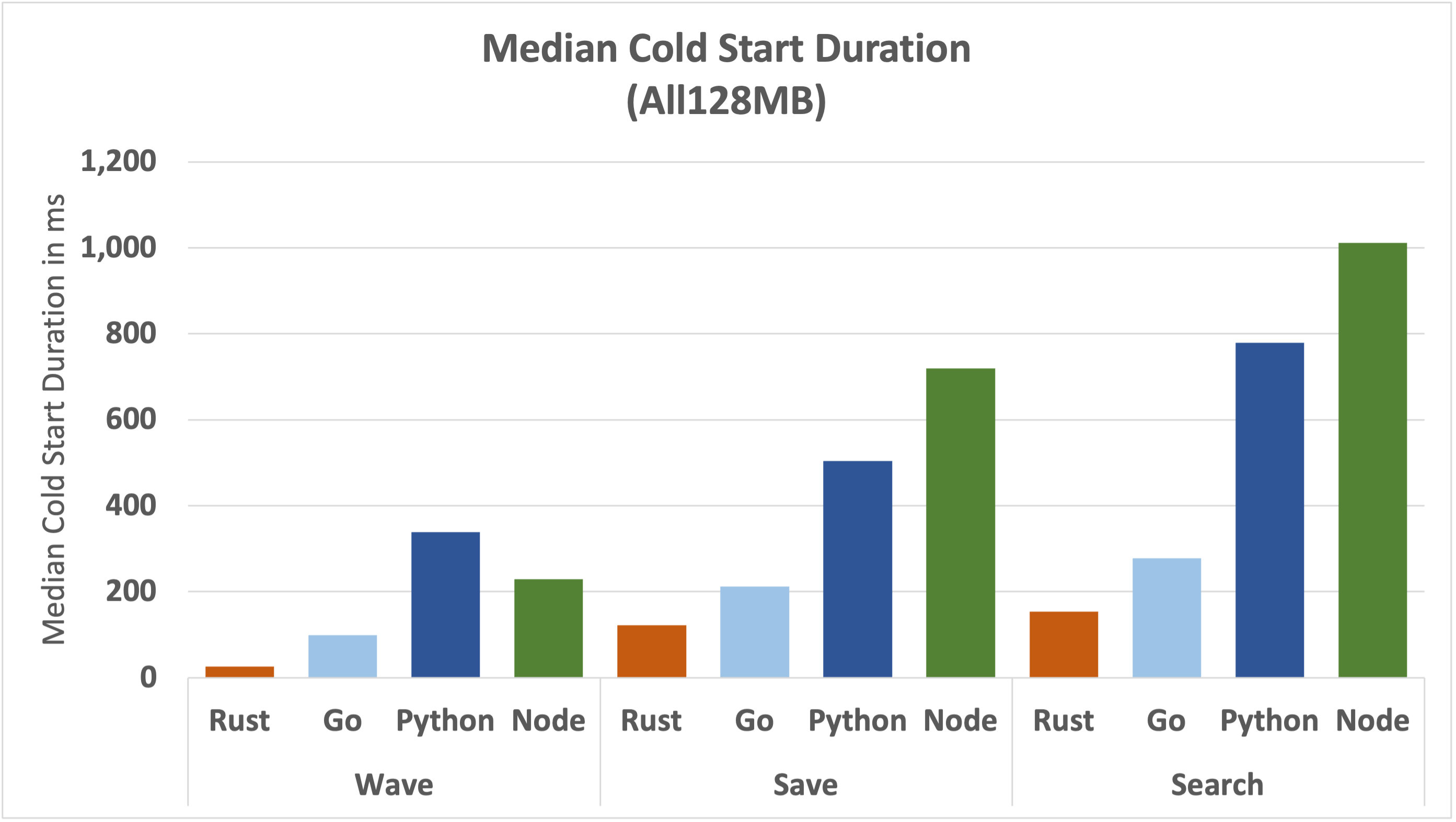
You might notice that this graph looks very similar to the Max Total Duration graph from above. It should, the worst of the outliers are driven by cold starts.
There are two elements to the cold start:
- Initialisation of a new function instance (Init Duration)
- The first execution of a new function instance
It can take a while for a new function instance to "warmup", depending on the runtime.
In the following graph, we'll look at Max Cold Start Duration vs Max Init Duration for every runtime and function.
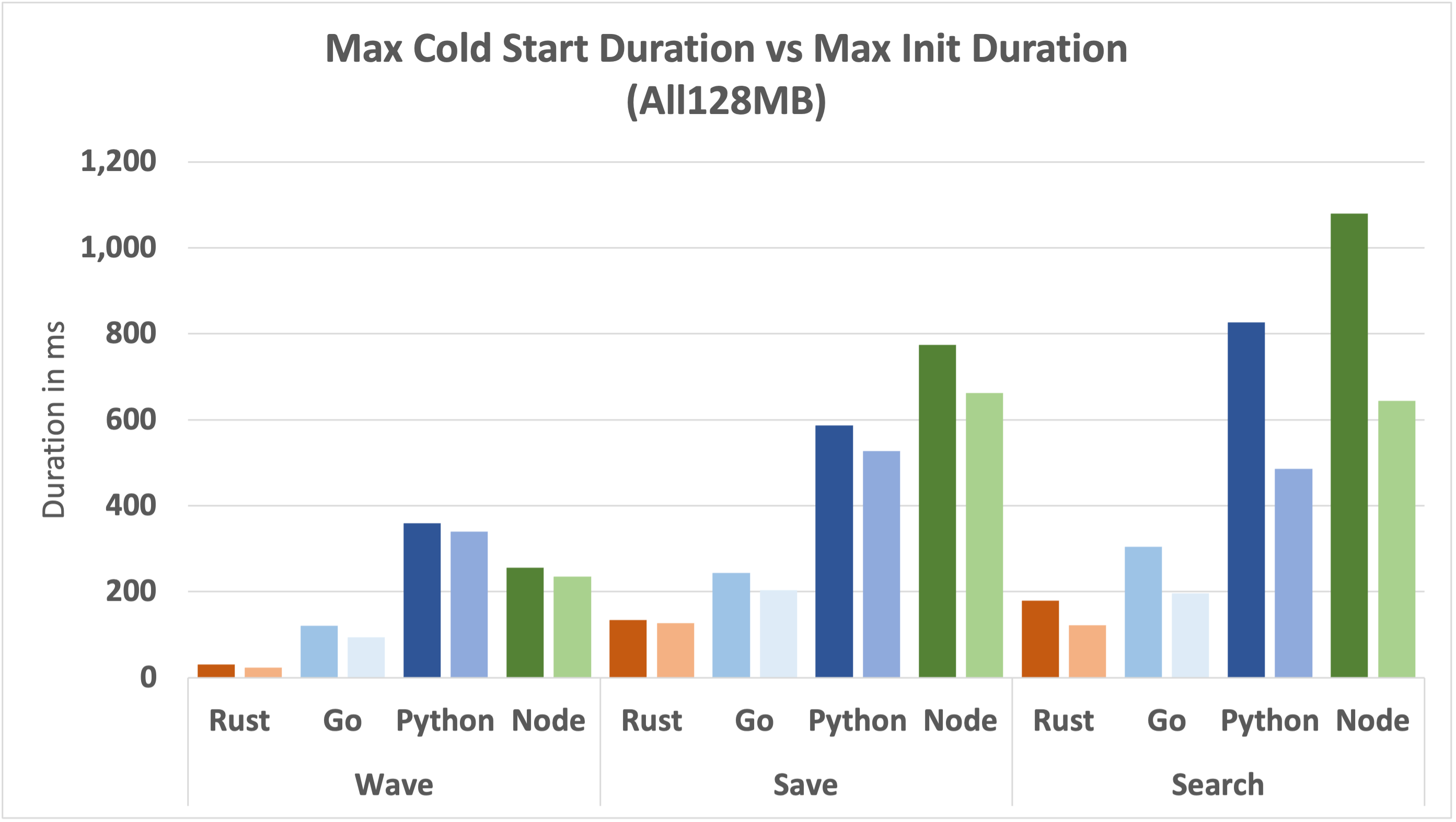
This is a busy graph. Each function has a pair of bars, the darker one on the left shows the Max Cold Start Duration and the lighter one on the right shows the Max Init Duration. The difference between the two can be read as the time taken to execute the first invocation of a new function instance, the time to "warmup".
We can see that as the function complexity increases, the gap between the cold start and the init duration increases, meaning the time taken to execute the first invocation increases. This is particularly true for Python and Node.
Memory Usage
Another factor that can impact performance is max memory usage. The three functions in this analysis are all fairly simple and can execute within the smallest 128MB configuration. We'll explore increasing the memory configuration (which also boosts CPU) when discussing Mitigations.
Let's take a look at how max memory usage compares between runtimes.
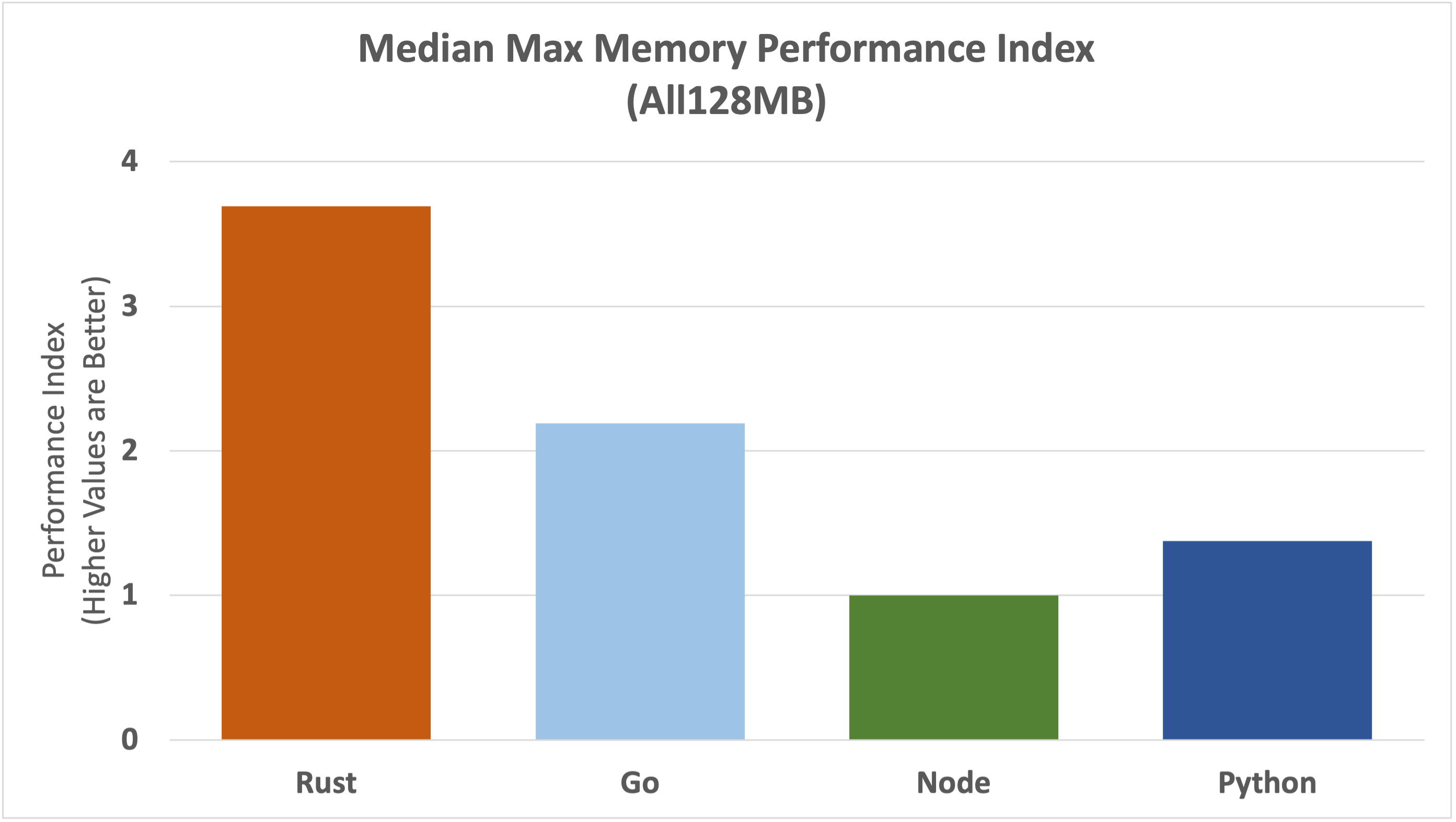
Rust uses the least amount of memory, followed by Go and then Python, with Node using the most memory.
Let's take a look at the underlying numbers for each runtime and function.
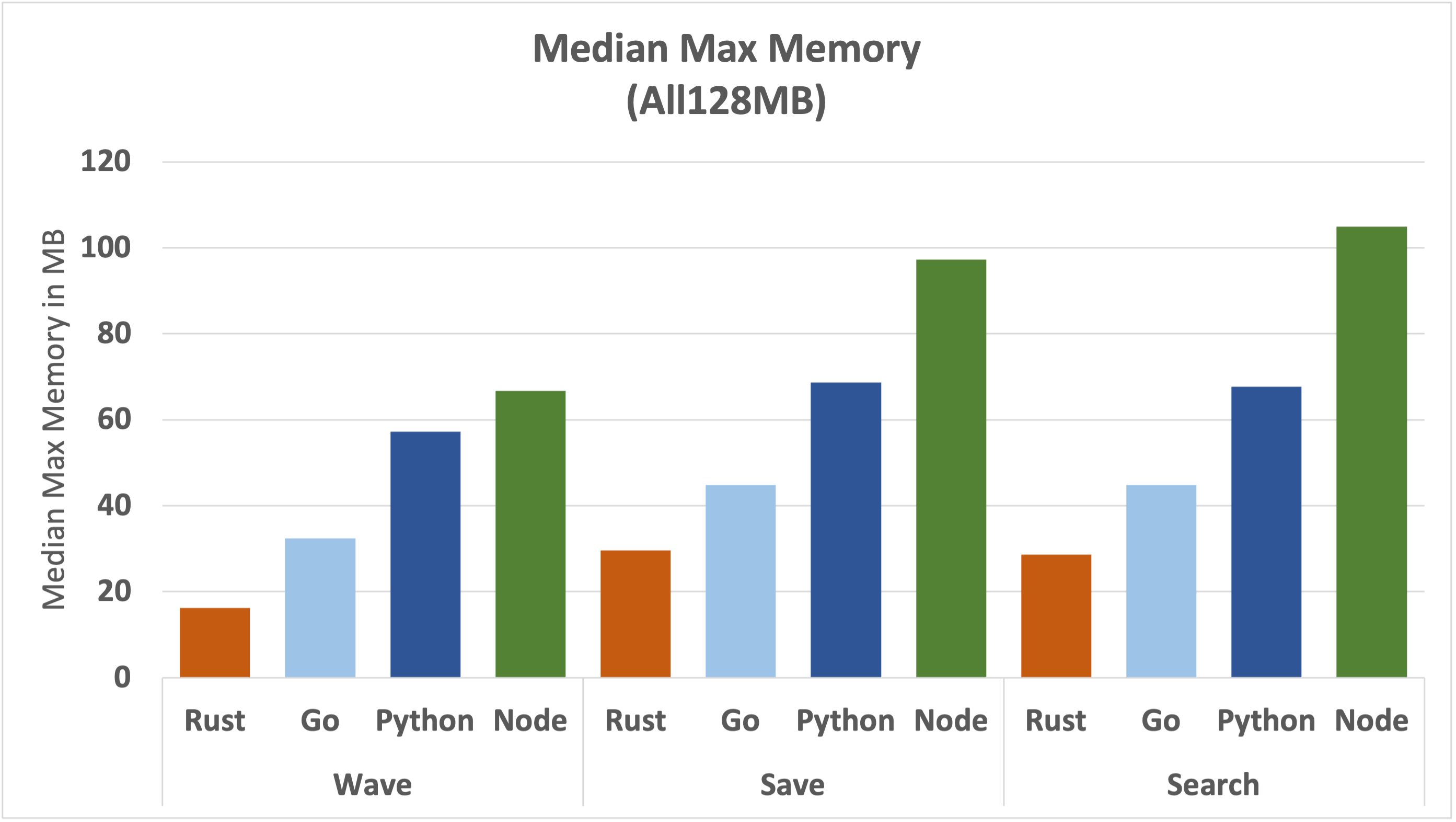
There are several observations we can take from this graph:
- There's a step up in max memory used between the Wave function and the other two functions for all runtimes. This is mainly because of the additional modules required for geohash calculations and DynamoDB interaction.
- The memory used by Rust, Go and Python is well under the 128MB ceiling.
- Node memory usage gets uncomfortably close to 128MB. This could lead to excessive garbage collection and poor performance.
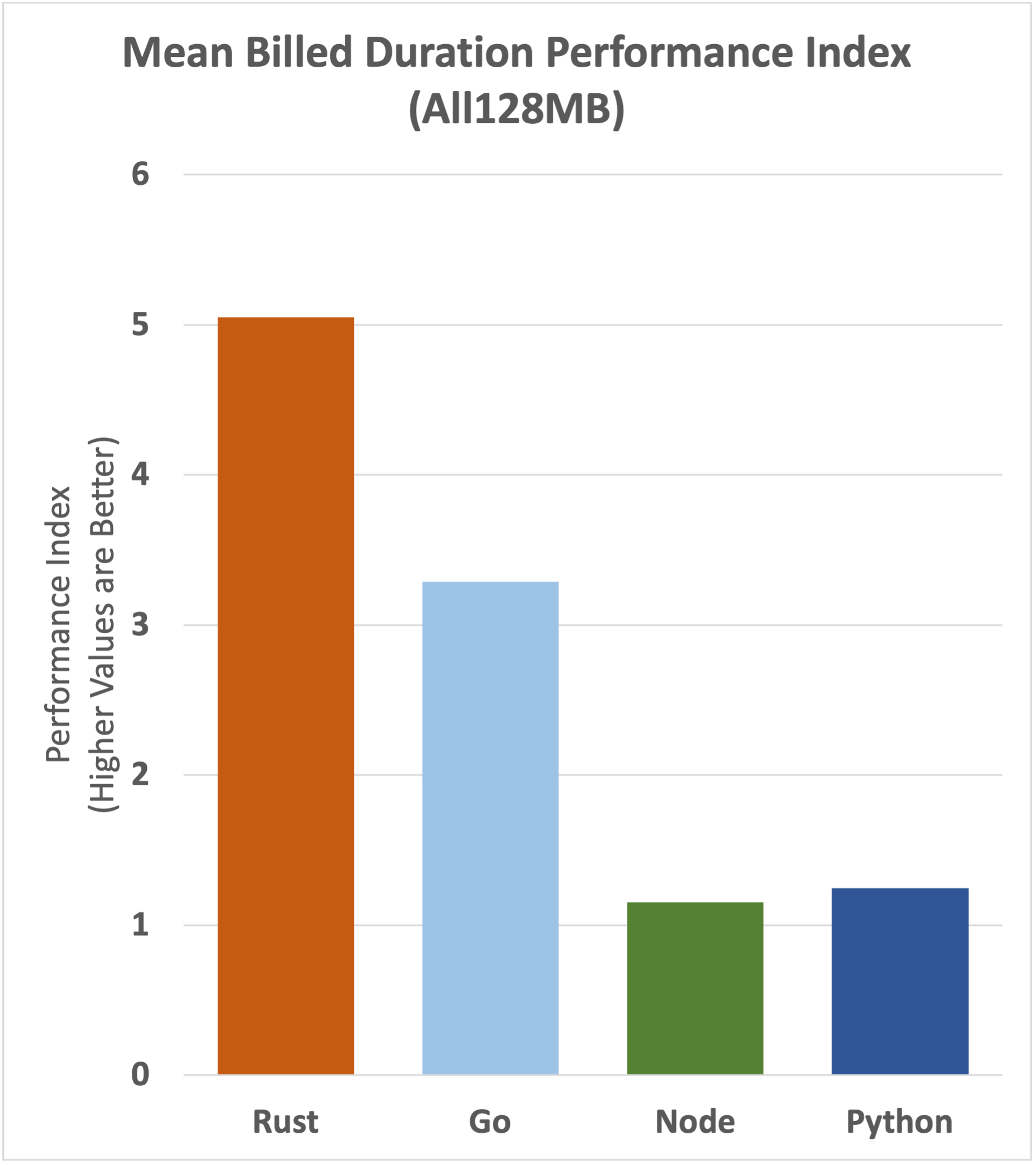
Billed Duration
Basic AWS charges for lambda functions include the execution time, rounded up to the nearest millisecond. For managed runtimes the billed duration excludes the initialisation time, but for custom runtimes the billed duration includes the initialisation time. As things stand today, Rust is a well-supported but custom runtime.
So does that blow the cost advantage enjoyed by Rust out of the water? Let's take a look.

Despite the cost treatment disadvantage, Rust is still the most cost-effective runtime in these benchmarks, although the gap to Go narrows a little compared to straight-out performance.
Let's take a more detailed look at the underlying data.
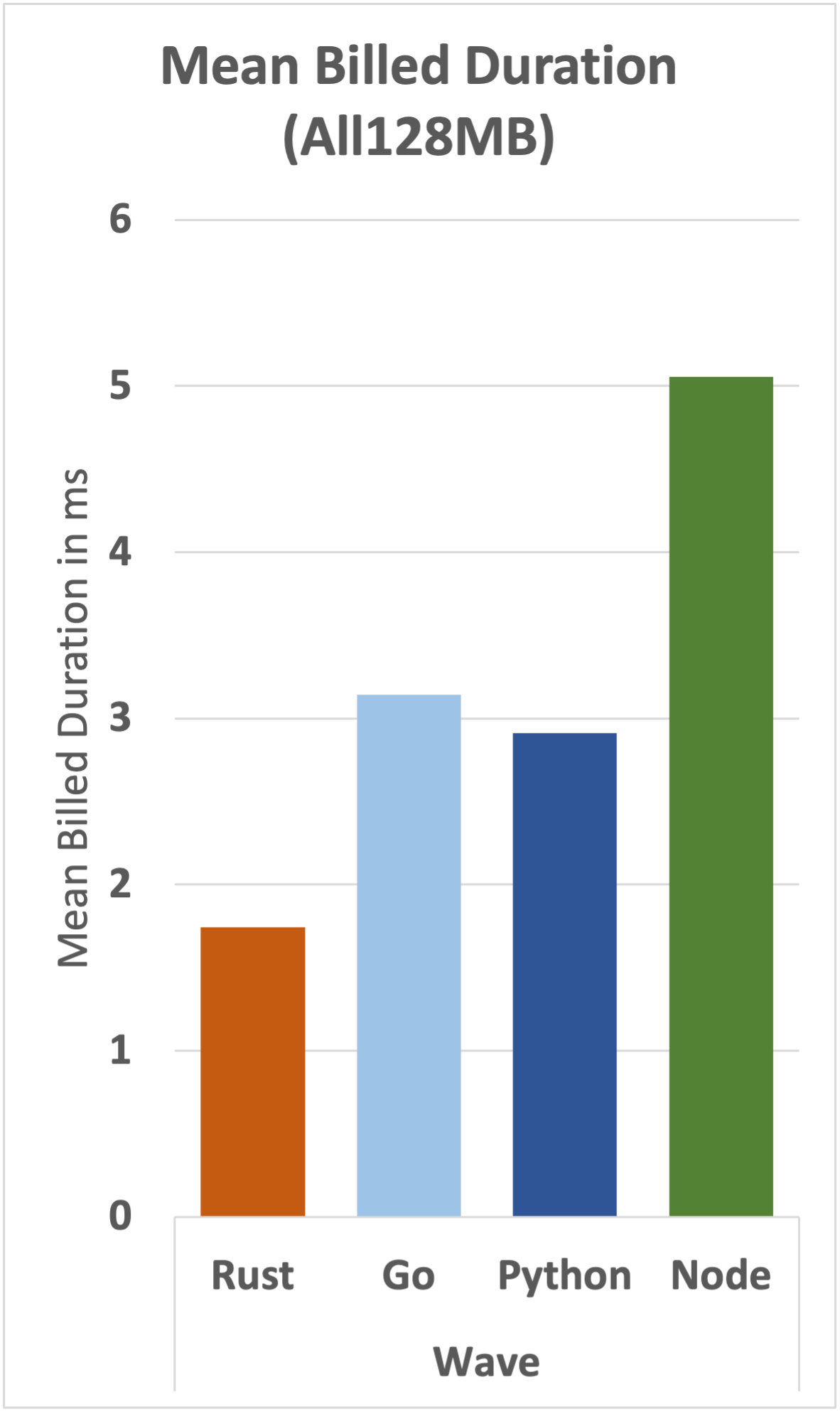
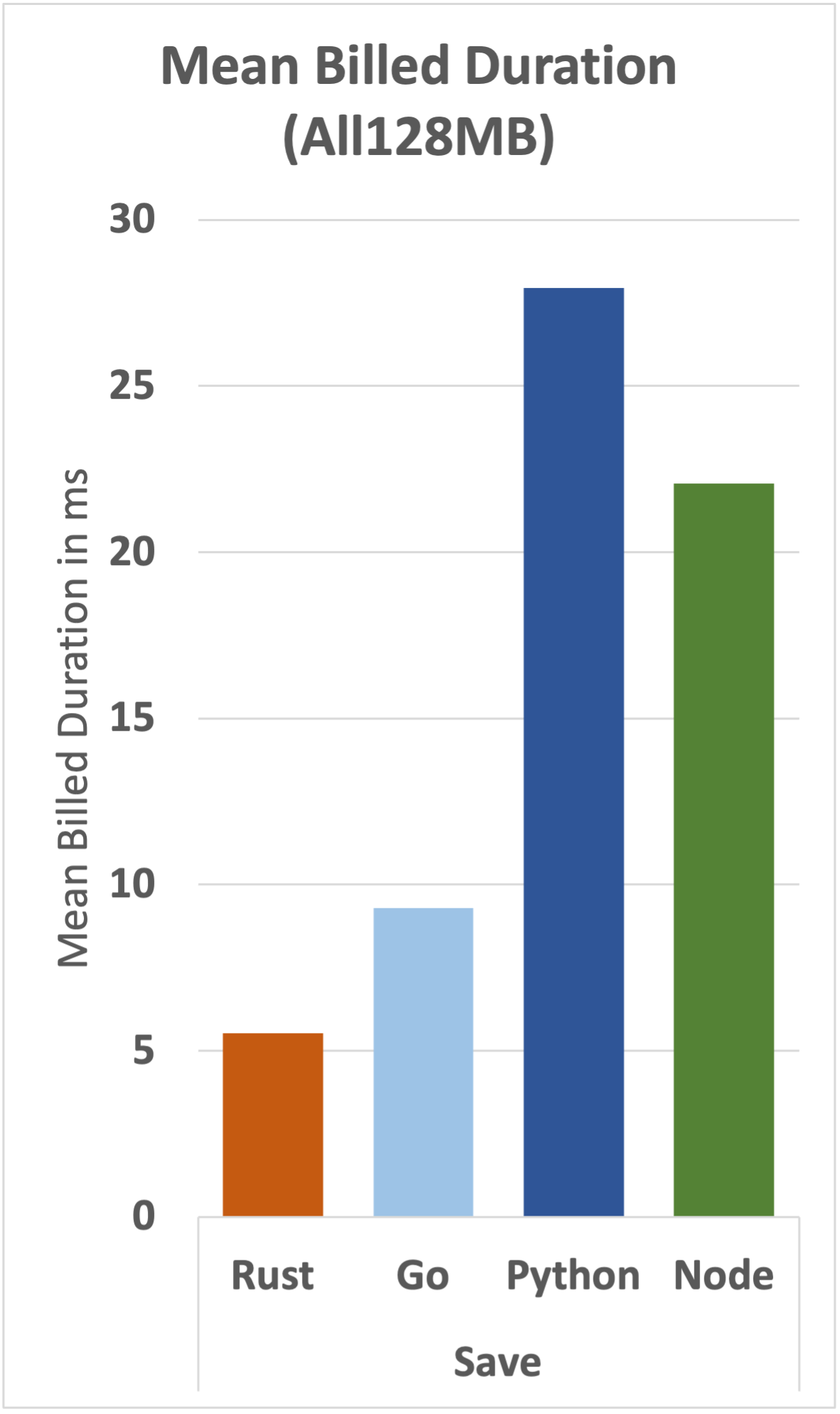
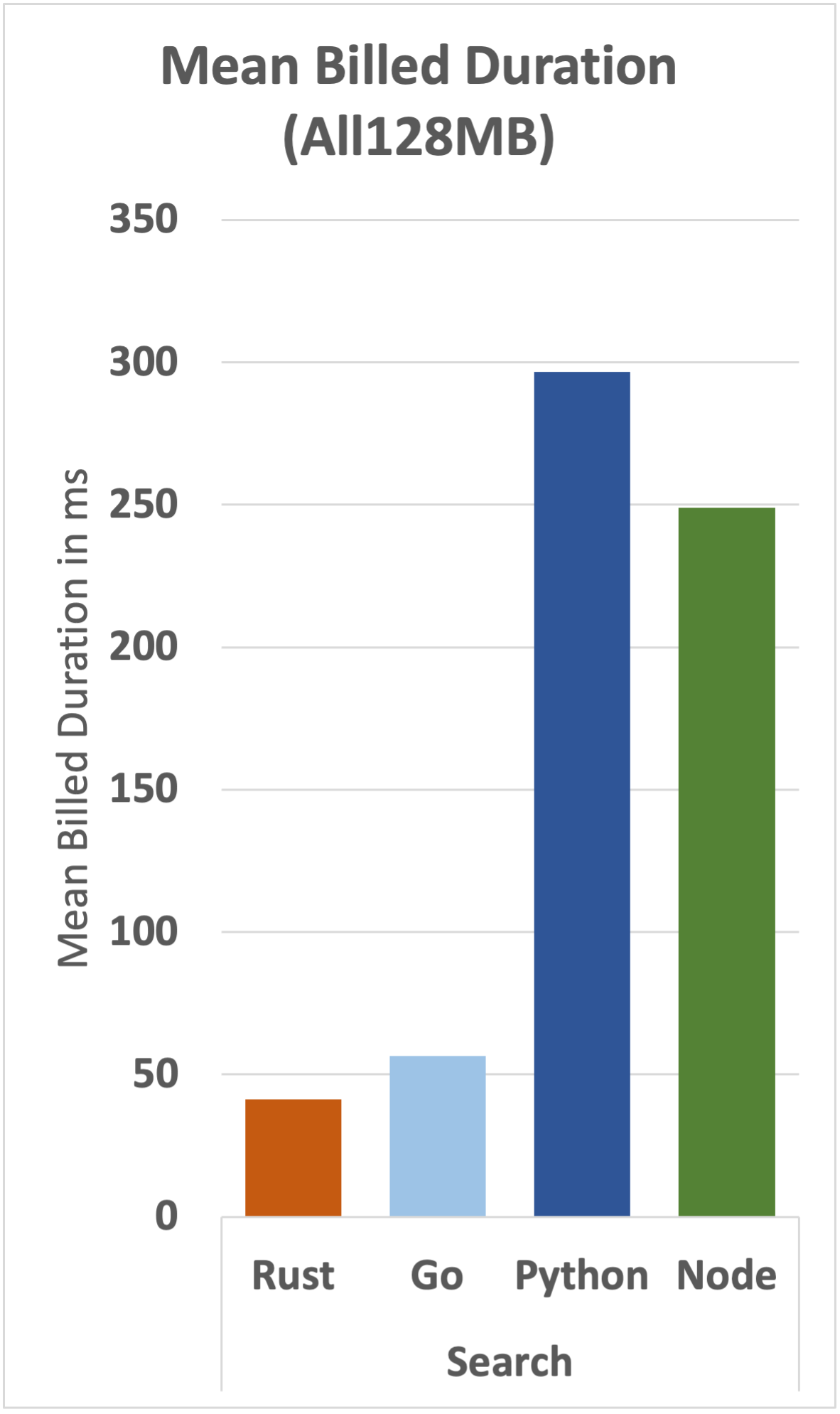
We can see that the cost advantage that Rust has over Go is maintained for all functions, although the gap narrows as complexity increases.
Rust gets saved here by its fast and stable cold start performance. Regardless of these specific results, this is an issue to be aware of when you're assessing which runtime to use for a particular use case.
Mitigations
Various mitigations for poor lambda performance can be considered, including:
- Increasing lambda memory configuration
- Provisioned concurrency
- Code optimisation
- AWS Lambda SnapStart
This post will consider the first three of these mitigations only.
AWS Lambda SnapStart is only available for Java 11 runtimes, this might change in the future.
Increasing Memory
Increasing the memory configuration for a lambda function not only provides an obvious increase in processing headroom but also boosts CPU performance. Memory and CPU can't be configured separately.
Increasing memory also increases the cost per millisecond, regardless of how much of the configured memory is used. The duration charge is on a GB per second basis; double the configured memory and you double the cost per millisecond. However, your lambda function should also run faster so you'll be paying for fewer milliseconds.
It's possible that increasing memory could reduce costs in certain cases, so it pays to test for your specific use case.
Let's compare the performance index of the benchmark runs using 128MB and 256MB memory configurations. On the left, we have the numbers we've already seen for the 128MB configuration, while on the right, we have new numbers for the 256MB configuration.

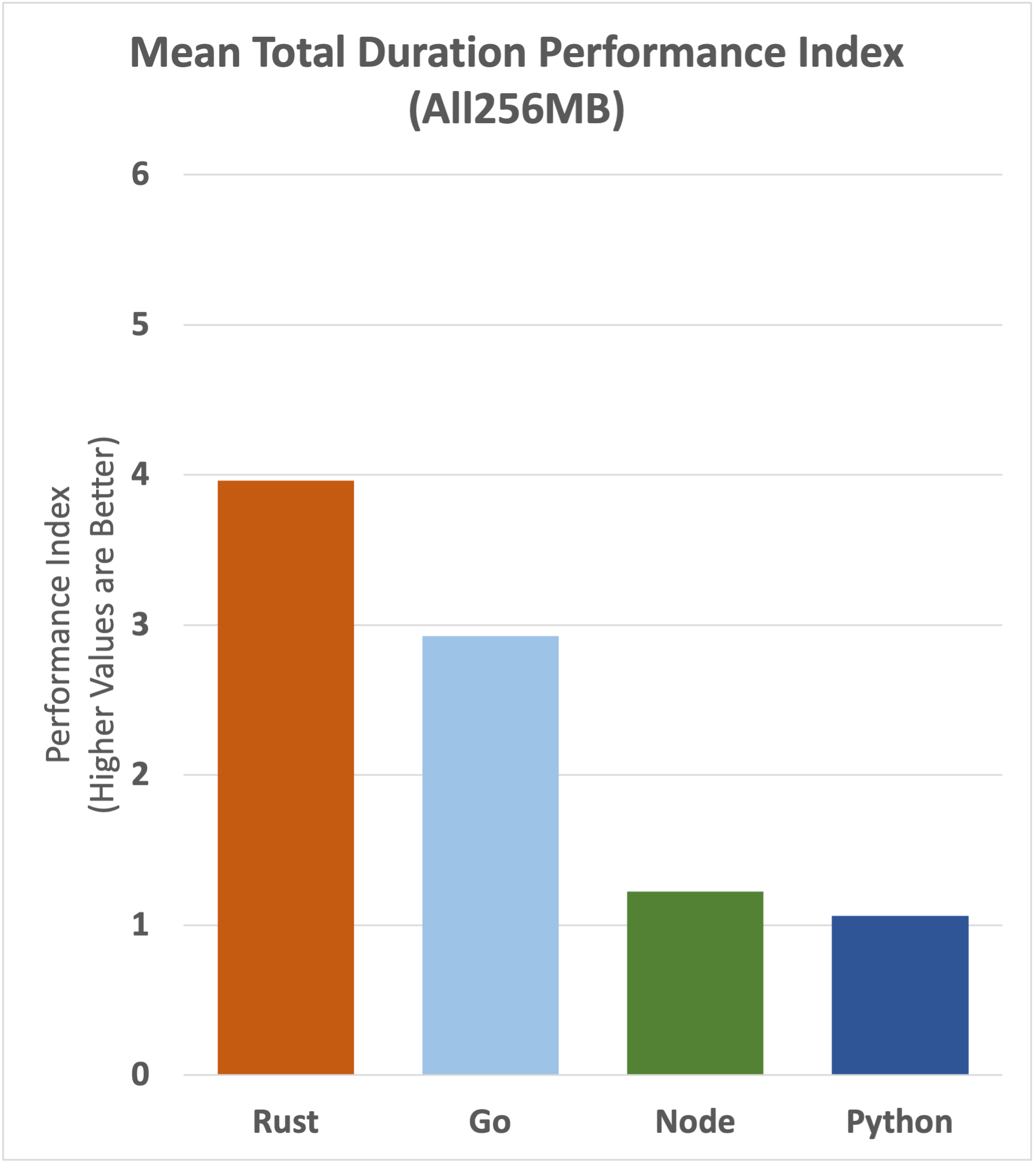
The performance gap has narrowed with Rust being the main loser. This is no surprise, Rust works well in low memory configurations and has the least to gain by increasing memory.
Let's take a look at how the worst-case outliers compare.
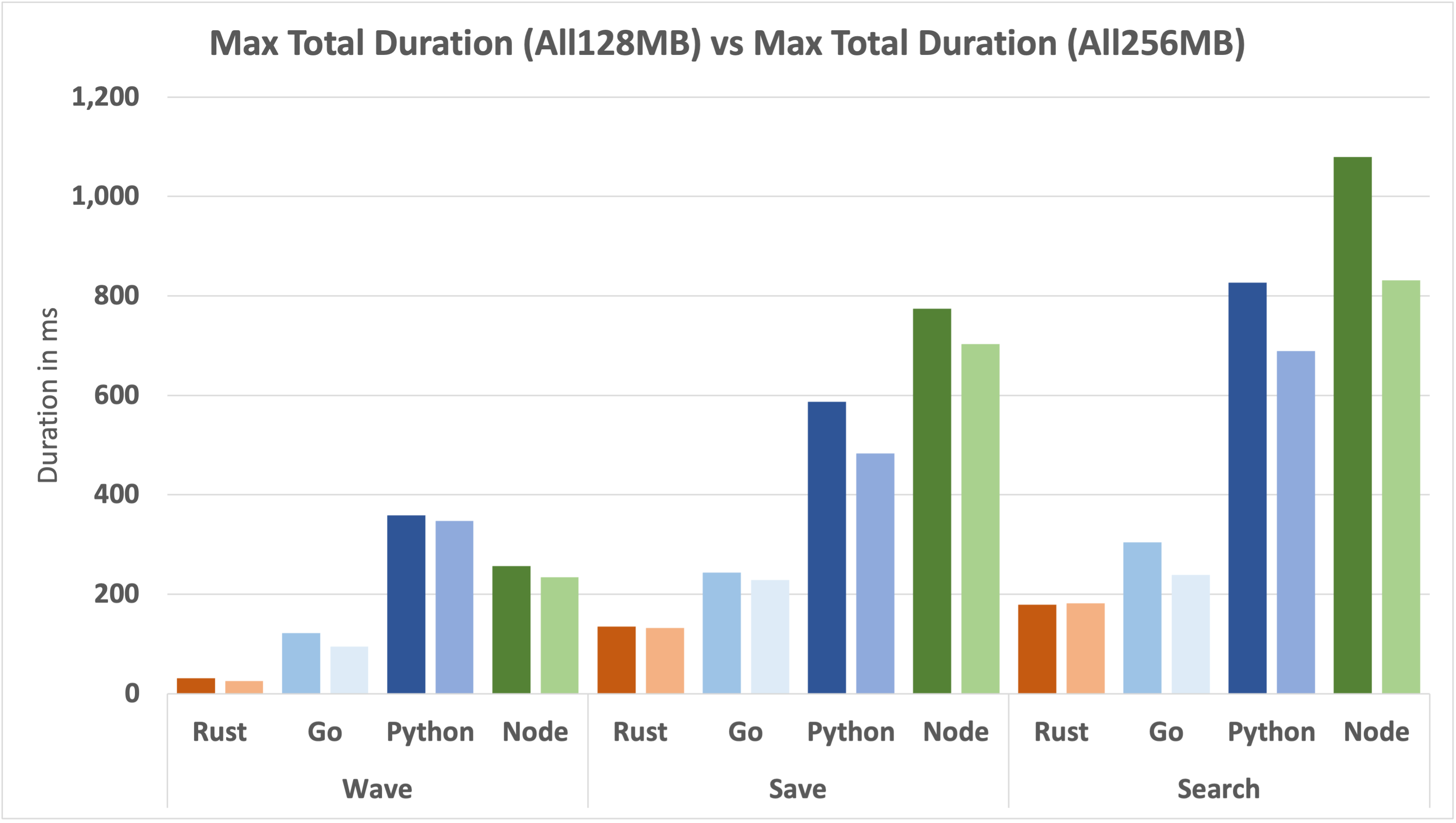
This is another busy graph where each function has a pair of bars, the darker one on the left shows the 128MB value and the lighter one on the right shows the 256MB value. Node, Python and Go have clearly benefited from the extra memory when it comes to the worst-case as well. Rust is little changed but still offers superior performance by a decent margin.
Finally, let's take a look at how billed duration has been impacted in relative terms.
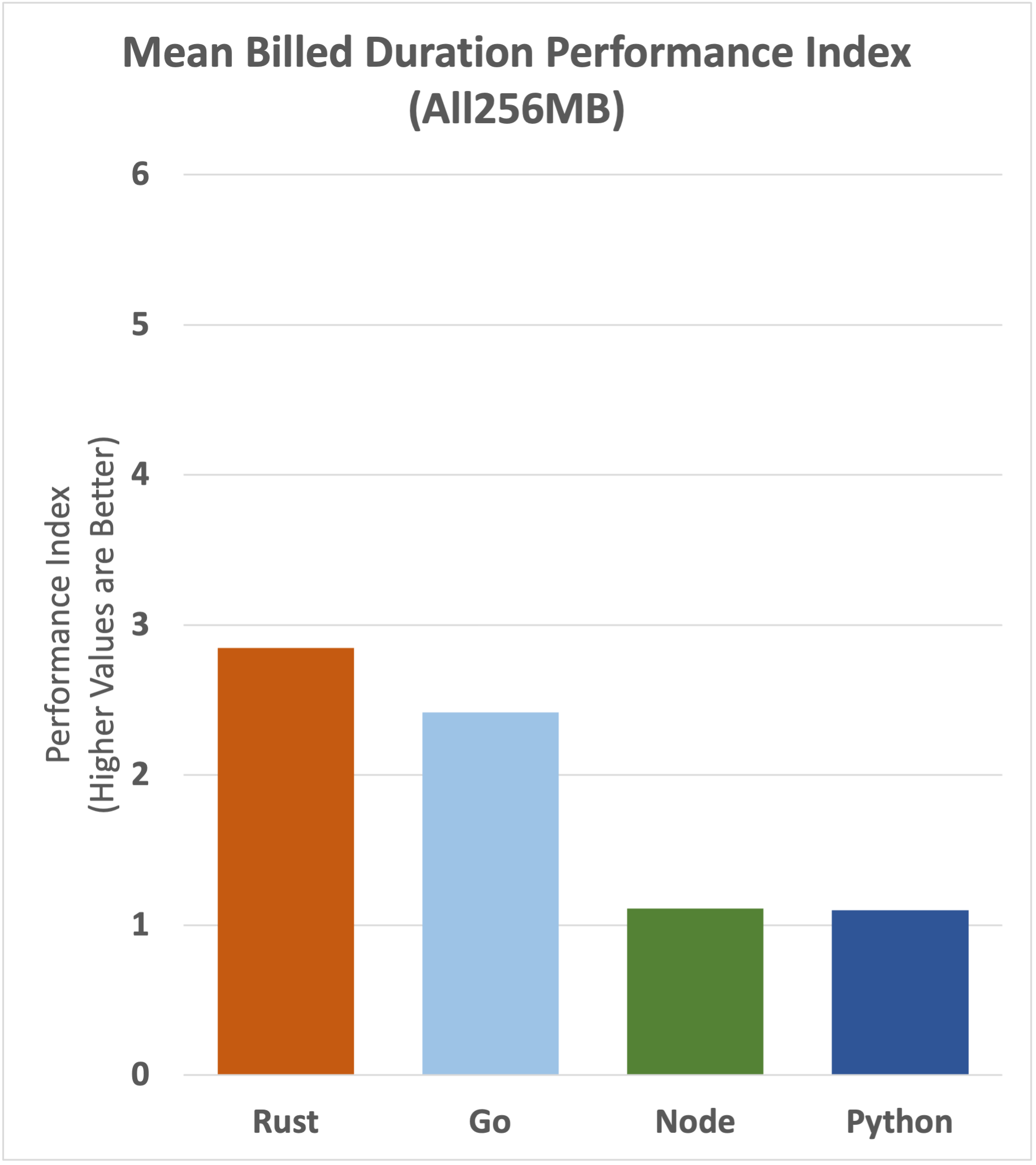
Rust appears to lose a large part of its cost advantage here, but we have to remember that rust doesn't need 256MB of memory to provide fast, consistent performance. Where you may need higher memory configurations for Node, Python and Go, Rust will continue to deliver excellent performance on the cheaper memory tier.
Provisioned Concurrency
Provisioned concurrency was introduced by AWS to mitigate the cold start issue.
While running a full provisioned concurrency benchmark is out of scope for this analysis, we can still draw some conclusions from the data we have already seen.
If you're running Node or Python, then I'm sure that you're already using or considering provisioned concurrency.
If you're running Rust and maybe Go, then you may not need the added cost or complexity of provisioned concurrency. Rust and Go outperform the other runtimes across the entire distribution, and Rust has a relatively fast cold start.
Configuring provisioned concurrency to eliminate the possibility of a cold start can be complex and potentially expensive if it can be done at all. You need to be confident that any spike in user activity can be accommodated by your parameters.
We can already see from this analysis that removing the cold start from Node and Python won't get them close to the blazingly fast and consistent performance of Rust.
Here's what it looks like if we remove the Init Duration from Node and Python only.
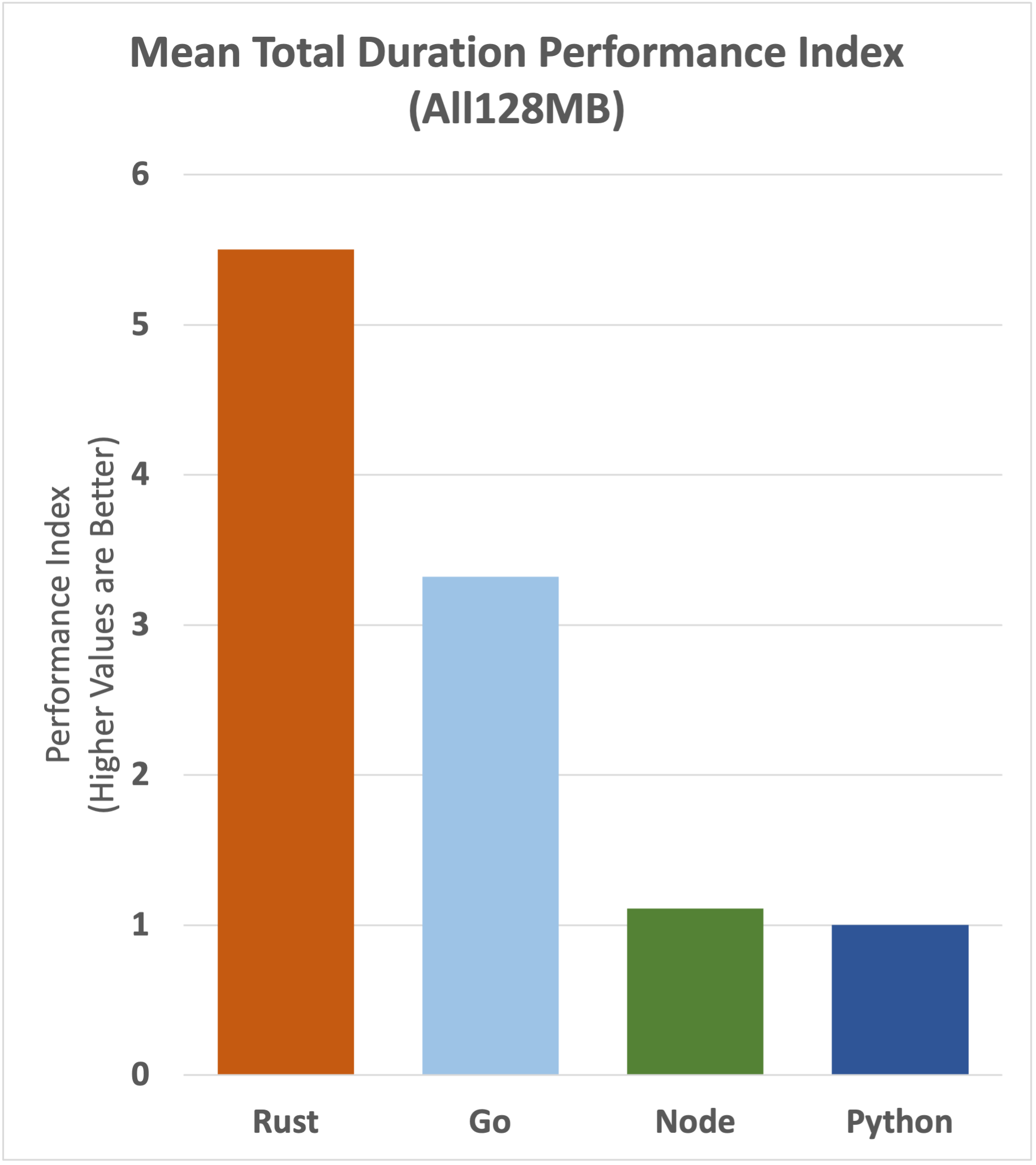
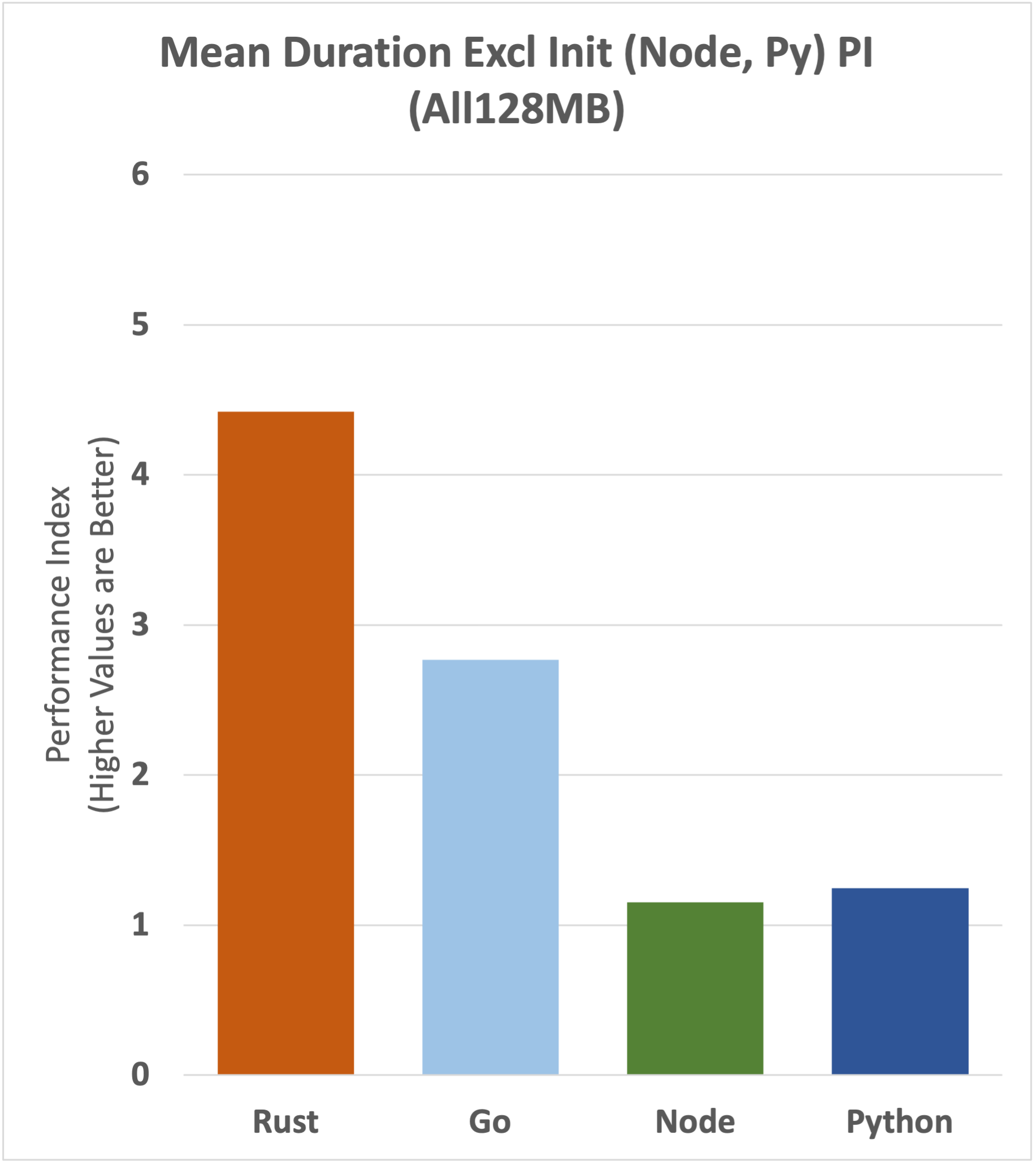
We can see that there's a narrowing of the gap, but that the performance advantage to Rust and then Go is still substantial.
Code Optimisation
Code optimisation would be considered in any real case. However, for this benchmark all of the functions have been implemented to a similar pattern, as far as language differences allowed. Optimisations would need to be performed on every runtime in equal measure and that's beyond the scope of this analysis.
There is an obvious optimisation that's worth taking an initial look at. The Search function makes nine DynamoDB queries when it executes the geospacial search; one for the geohash containing the query coordinates and one for each of the eight surrounding geohash values.
It would be logical to perform the asynchronous DynamoDB calls concurrently.
Let's take a look at how an optimised concurrent search function (Conc) improves over the existing single-threaded search for each of the runtimes.
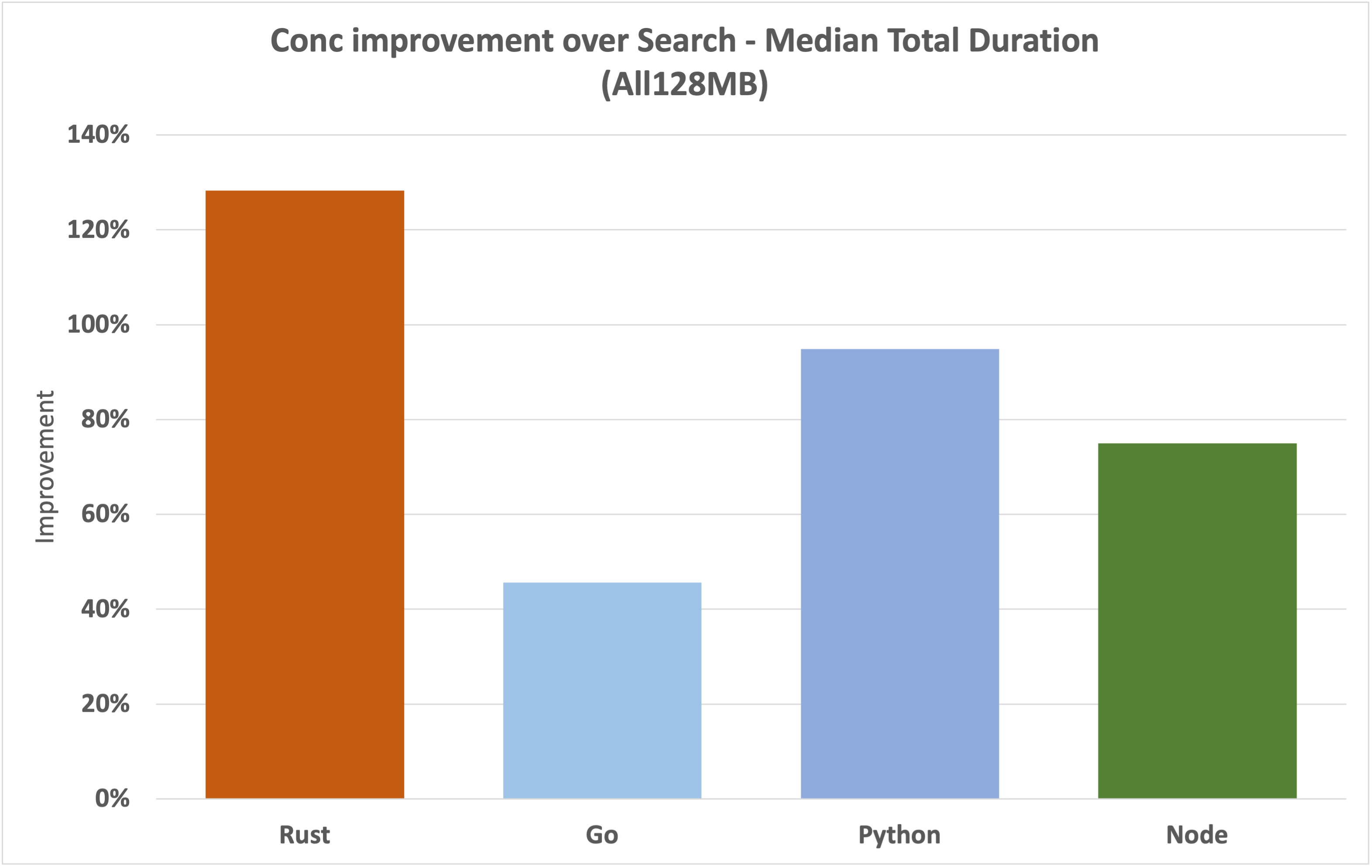
We can see a solid improvement of over 120% for Rust, almost 100% for Python, almost 80% for Node, and a more modest improvement for Go of just over 40%.
Let's compare using the 256MB dataset.
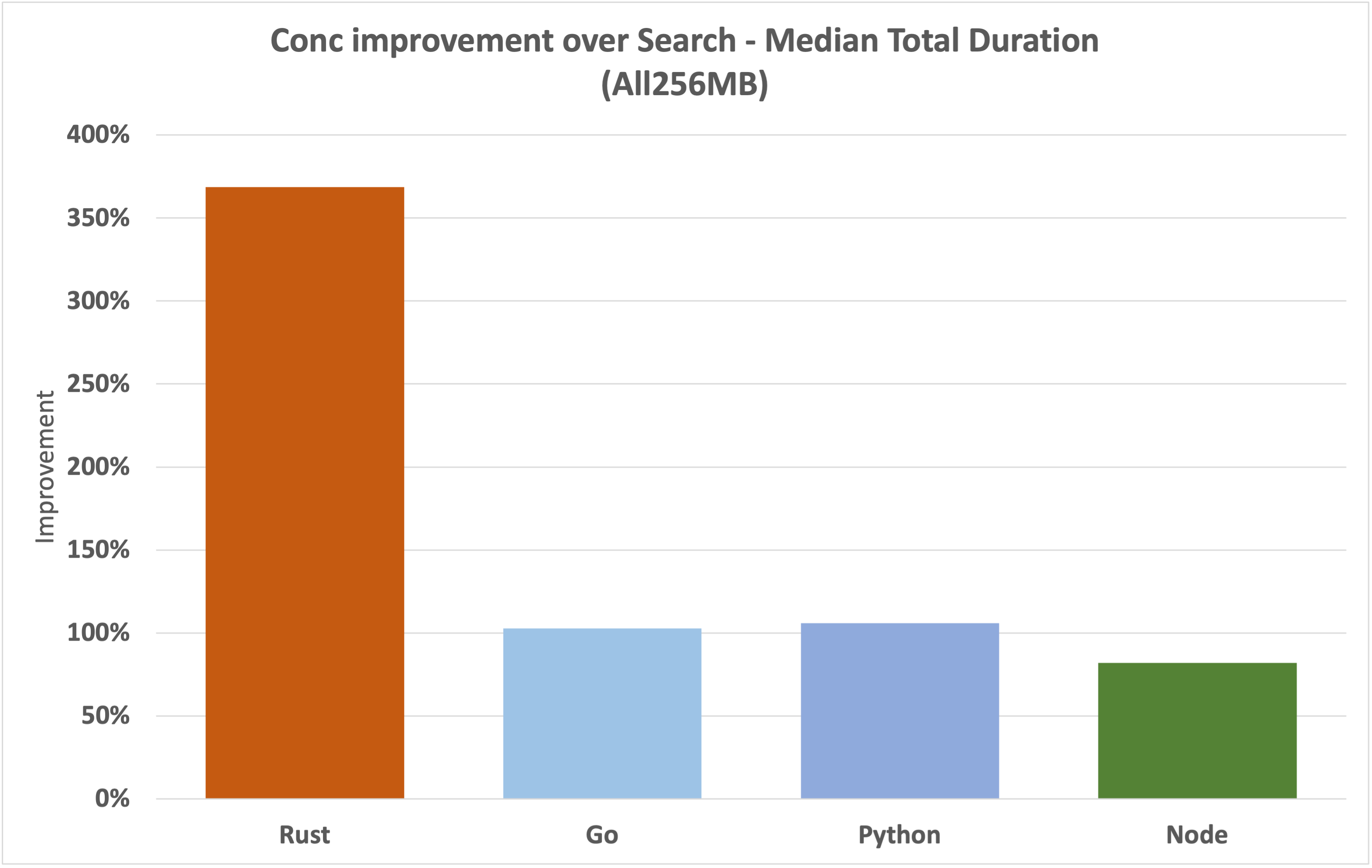
Rust sees massive improvement here, translating to a sub 6.5ms median geospatial search duration. Go gets a nice relative improvement, moving alongside Python at around 100%. Even though the max memory used by Go is nowhere near 128MB, it consistently benefits from the 256MB configuration.
As far as ease of implmentation goes:
- Node was the easiest to optimise and worked on the first attempt
- Rust was also fairly easy to optimise and also worked on the first attempt
- Go took a little longer to get right but that was probably on me
- Python took the longest and required an alternative module (aiodynamo)
Rust is the clear winner in terms of pure performance gain.
Conclusions
This analysis has focused solely on runtime performance and we know that there are many other considerations to take into account when selecting a technology.
While Python and Node didn't perform well in this analysis, they have some big advantages of their own:
- Huge user communities providing extensive support and a large talent pool
- An extensive array of modules and tooling for just about anything you might practically need
- They are concise languages offering ease of learning and high productivity
Rust, on the other hand, has a fairly steep learning curve and a small, although active, user community. Go occupies a middle ground; it can perform almost as well as Rust in some cases, but it requires more memory and exhibits larger outliers.
What this means on balance comes down to your specific use case and preferences. The performance of Rust is compelling, but it's a heavy lift in other ways.
Why did Rust perform so well? I'll put it down to these two major advantages:
- Rust is natively compiled (as is Go)
- Rust has deterministic memory management with no garbage collector
For my part, I'll recommend and use Rust whenever it's a viable option. Any potential productivity loss can be countered through expertise and tooling, and the end product is just too compelling to pass up.
Having Rust capabilities within your team can lead to excellent outcomes, particularly if you prioritize blazingly fast and consistent performance, which can offer a superior user experience, cost reduction, and a lower environmental footprint.
Credits
Serverless Land Patterns provide an excellent starting point for a range of serverless runtimes and configurations. This website has some great articles and sample content.
I used Apache ab to drive the benchmarking load.
ChatGPT got me out of a tricky situation or two.